MySQL从建表到删库
MySQL的连接
通过执行mysql -u 用户名 -p,并输入密码即可连接数据库。
在连接到MySQL后,可以通过show databases列出所有的数据库,并使用use 数据库名来选择数据库。
使用create databse 数据库名可以创建新的数据库;使用drop database 数据库名可以删除已有的数据库。
执行exit或quit即可退出MySQL。
数据类型
MySQL的数据类型可以分为三种:数值、日期(时间)和字符串(字符)类型。
数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32768,32767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8388608,8388607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2147483648,2147483647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9,223,372,036,854,775,807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402823466E+38,-1.175494 351E-38),0,(1.175494351E-38,3.402823466351E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.7976931348623157 E+308,-2.2250738585072014E-308),0,(2.2250738585072014E-308,1.7976931348623157E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期和时间类型
| 类型 | 大小 ( bytes) |
范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’ | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-19 03:14:07’ UTC 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYY-MM-DD hh:mm:ss | 混合日期和时间值,时间戳 |
字符和字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
其他数据类型
枚举和集合类型
- ENUM: 枚举类型,用于存储单一值,可以选择一个预定义的集合。
- SET: 集合类型,用于存储多个值,可以选择多个预定义的集合。
空间数据类型
GEOMETRY, POINT, LINESTRING, POLYGON, MULTIPOINT, MULTILINESTRING, MULTIPOLYGON, GEOMETRYCOLLECTION: 用于存储空间数据(地理信息、几何图形等)。
数据表
创建数据表
以下为创建数据表的通用写法:
1 | CREATE TABLE table_name( |
table_name:要创建的数据表名。column:每一列的名称。datatype:列的数据类型。
例如:1
2
3
4
5
6CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
is_active BOOLEAN DEFAULT TRUE
)- 数据库名为
users。 id: 用户 id,整数类型,自增长,作为主键。username: 用户名,变长字符串,不允许为空。email: 用户邮箱,变长字符串,不允许为空。is_active: 用户是否已经激活,布尔类型,默认值为 true。
删除数据表
使用drop table 数据表名即可删除数据表。
MySQL基本语法
插入数据
通过insert into命令可以向数据表中插入数据:
1 | INSERT INTO table_name(column1, column2, column3) |
如果要插入的值是字符类型,则需要使用''或者""。
1 | INSERT INTO users(username, email, is_active) |
如果要插入所有的数据,则可以省略数据表的列名。
1 | INSERT INTO users |
如果要插入多组数据,可以在values中指定多组数据,并使用,分隔数值。
1 | INSERT INTO users(username, email, is_active) |
查询数据
查询数据的基础用法为:
1 | SELECT column1, column2, ... |
如果要查询一张表的所有数据,可以使用*表示选择所有列。
1 | SELECT * FROM users; |
select语句后面还可以附加一些子句。例如where条件选择子句,order by排序子句和limit限制行数子句。
更新数据
使用update可以更新数据表中的数据:
1 | UPDATE table_name |
例如,将用户名为soria的用户的激活状态改为未激活:
1 | UPDATE users |
我们还可以使用表达式进行更新。例如,将肉类产品的价格提高10%:
1 | UPDATE foods |
删除数据
使用delete可以删除数据表中的数据:
1 | DELETE table_name |
例如,删除名为soria的用户:
1 | DELETE users |
如果不添加where子句,那么将会删除所有行,但数据表依旧存在。
1 | DELETE users; |
MySQL子句
WHERE条件选择子句
where子句用于在MySQL中过滤查询结果,只返回满足特定条件的行,类似于程序设计语言中的if。
1 | SELECT column |
例如,我们需要在users表中查询名为soria的用户:
1 | SELECT * |
我们也可以使用AND或OR来筛选多个条件。例如,我们需要查询名为soria且已激活的用户:
1 | SELECT * |
我们还可以使用一些操作符,例如>、<、>=、<=、=、!=。具体用法和程序设计语言中相同。
1 | # 查询用户名不为soria的用户:!=、NOT |
如果给定的条件在表中没有任何匹配的记录,那么查询不会返回任何数据。WHERE子句还可以用于更新数据和删除数据,不仅仅是用作查询。
ORDER BY排序子句
使用order by可以对一个或多个列进行升序(ASC)或降序(DESC)排列。
例如,将年龄小于20岁的学生按照数学成绩降序排列:
1 | SELECT * FROM students |
还可以按照多个列进行排序。例如,将学生按照班级升序排列,再在相同班级中按照总分降序排列。
1 | SELECT * FROM students |
用数字代表列进行排序也可以,但是不常用。例如,将某个表按照第一列降序,再按照第二列升序排列。
1 | SELECT * FROM table_name |
[!NOTE]
自MySQL 8.0.16后,可以使用NULL FIRST或NULL LAST将NULL值排在最前或最后。
例如,查询商品名称和价格,并按照价格降序排列,将NULL值排在最后:
2
3
FROM goods
ORDER BY price DESC NULL LAST;
LIMIT限制行数子句
limit用于限制返回的行数。例如,查询10名年龄小于18岁的学生:
1 | SELECT * FROM students |
LIKE子句
♥️喜欢你~♥️LIKE子句用于在WHERE子句中进行模糊匹配。在LIKE子句中,使用%来表示零个或多个字符,使用_来表示单个字符。
例如,%a_可以匹配任意字符+a+单个字符,例如:cbac、pppac、ab。
1 | # 匹配商品名称中含有a的商品 |
LIKE子句还可以使用[]通配符。[]表示匹配其中的字符任意一个,[^]表示匹配不在其中的字符任意一个。例如,[abc]表示匹配包含a、b、c三个字符的任意一个。
1 | # 匹配商品名称中不含a、b、c的商品 |
GROUP BY分组语句
group by可以根据一个或多个列对结果进行分组。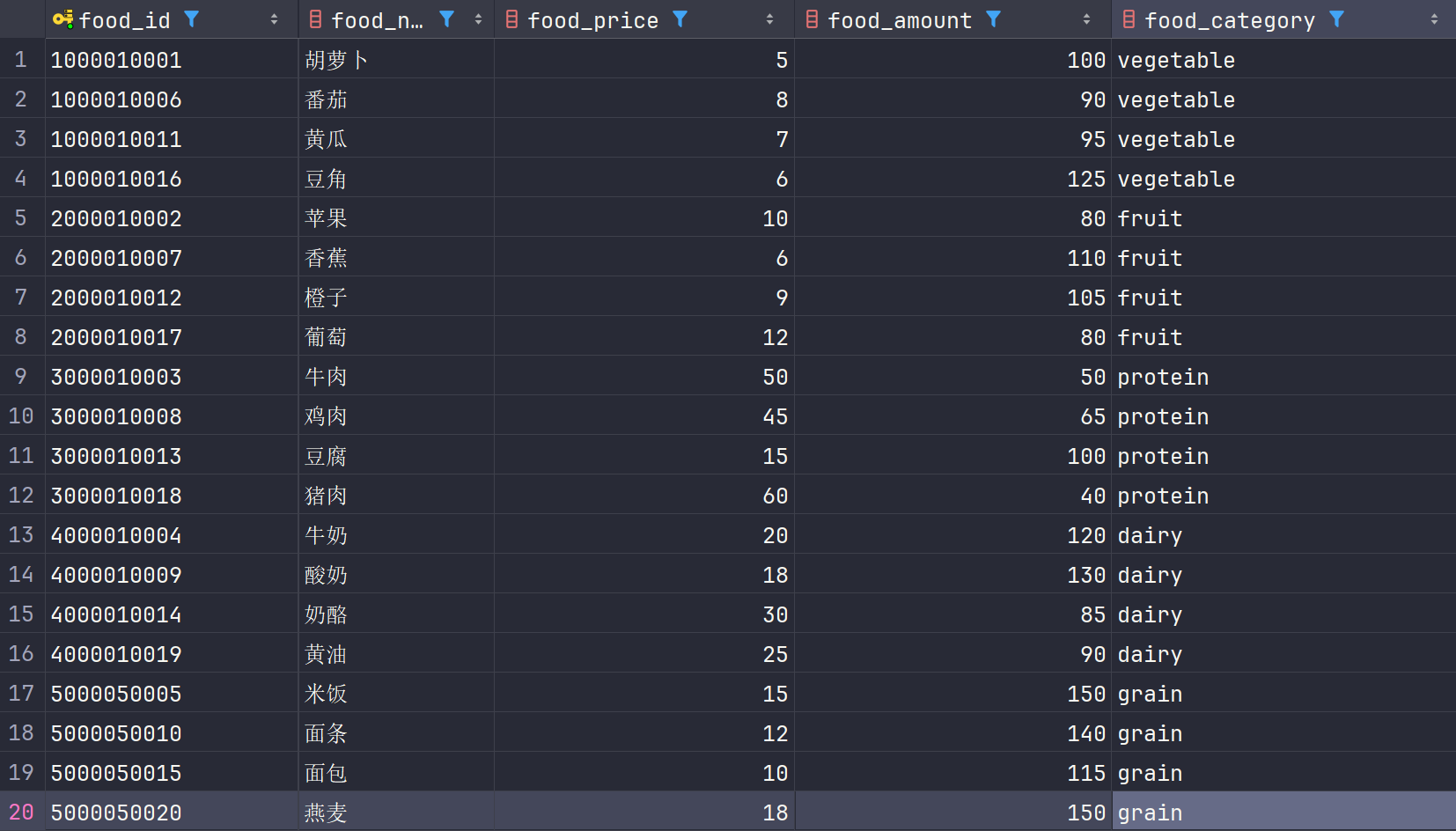
现有一张foods数据表,我们需要按照食物类别进行分类,并且计算出每种类别的食物总数量。
1 | SELECT food_category, SUM(food_amount) AS food_total |
执行上述语句后,我们会得到如下结果: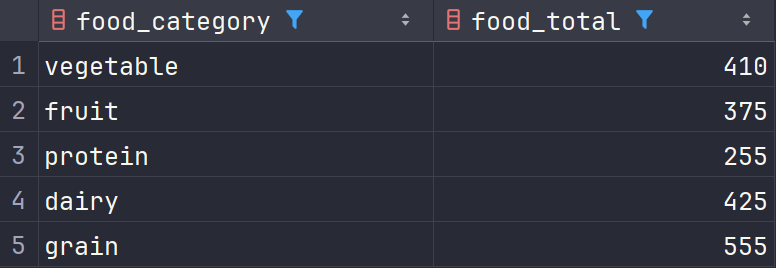
GROUP BY 子句通常与聚合函数一起使用,因为分组后需要对每个组进行聚合操作。
正则表达式子句
正则表达式子句REGEXP用于WHERE子句之后。
1 | SELECT column1, column2, ... |
其中,column_name是需要进行正则匹配的列,pattern是正则表达式匹配模式。
MySQL中的匹配模式只有编程语言的正则表达式的其中一部分。
| 模式 | 描述 |
|---|---|
^ |
匹配输入字符串的开始位置。 |
$ |
匹配输入字符串的结束位置。 |
. |
匹配除 “\n” 之外的任何单个字符。 |
[...] |
匹配所包含的任意一个字符。例如, [abc] 可以匹配 “plain” 中的 ‘a’。 |
[^...] |
和上述相反。 |
p1|p2|p3 |
匹配 p1 或 p2 或 p3。例如,apple|b|c可以匹配apple或b或c。 |
* |
匹配前面的子表达式任意次。例如,zo*能匹配 z、zo、zoo等。* 等价于{0,}。 |
+ |
匹配前面的子表达式至少一次。例如,zo+ 能匹配zo、zoo等,但不能匹配z。+ 等价于 {1,}。 |
? |
匹配前面的子表达式零个或一个。 |
{n} |
匹配确定的n次。例如,o{2}可以匹配zoo、food,但不能匹配lemon。 |
{n,m} |
最少匹配 n 次且最多匹配 m 次。 |
除上表外,还有一些字符匹配模式:
[a-z]:匹配小写字母。[0-9]:匹配数字。\w:匹配字母数字和下划线_。\s:匹配空白字符。
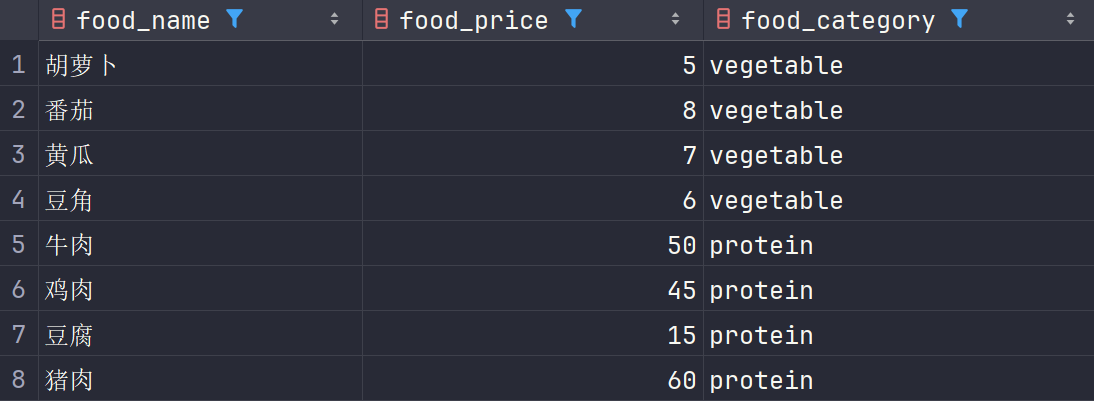
例如,我们要查询foods表中食物类别里至少出现了一次e的食物:可以得到如下查询结果:1
2
3select food_name, food_price,food_category
from foods
where food_category regexp 'e+';
MySQL进阶语法
UNION操作符
MySQL高级语法
- 微信
- 支付宝

