我在Java学斩神:JUC并发编程
我在Java学斩神。
先来个睡眠排序吧=v=
1 | public static void main(String[] args) { |
但我觉得还是猴子排序和意面排序更好
并发与并行
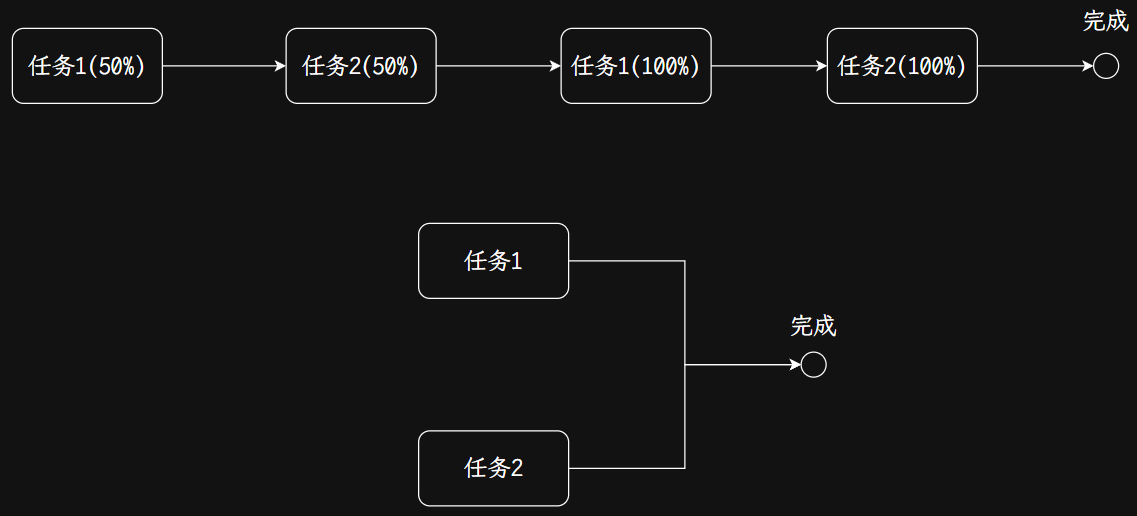
并发:在同一时间内只能执行一个任务,但是使用时间片轮转策略,多个任务轮流进行,直到完成所有任务。
并行:在同一时间内可以执行多个任务,直到每个任务都完成,然后汇总结束。
并发编程的三个特性:
- 原子性:一个操作要么执行成功,要么执行失败,不存在执行一部分。
- 可见性:多个线程访问同一个变量时,某个线程修改了这个变量,对其他线程是可见的。
- 有序性:程序执行顺序按照代码顺序进行。
Java内存模型(JMM)
JMM的规定如下:
- 所有的变量都存储在主内存,包括成员变量、静态变量、发生竞争的变量等。局部变量除外,局部变量属于线程私有。
- 每个线程都有自己的工作区域,线程对变量的操作必须在工作区域进行,不能直接操作主内存。
- 不同线程之间相互隔离,线程之间传递内容只能通过主内存进行。
线程如果要操作主内存中的数据,需要先将数据 copy 一份副本到工作区域,对副本操作完成后,再将副本 copy 一份到主内存中。即SL大法Save & Load 操作。
volatile 关键字
volatile 的特性
volatile保证可见性,不保证原子性。当定义了一个volatile变量时,JMM 会把该线程本地内存中的变量强制刷新到主内存中,同时,这个操作也会使其他线程中的volatile变量缓存无效。volatile还禁止了指令重排。指令重排是为了优化性能,但无论怎么重排序,最终的结果都不会变。但是这一条在多线程中将会失效,因此需要禁用它。
当执行到volatile变量时,其前面的所有语句都应该执行完,后面的所有语句都未执行,且前面语句的结果对后面语句可见。
1 | public static int count = 0; |
根据 JMM 的 S&L 操作,上述例子将在主线程修改count = 1后结束 while 循环。
但事实并不是这样。虽然我们在主线程中修改了 count,但是 Thread 并不知道,还是在用以前的 count 进行判断。因此,普通变量并不具备可见性。
1 | public static volatile int count = 0; |
我们可以使用volatile保证其可见性,但并不保证原子性。因为,只要线程执行的够快,就有可能会出现两个线程同时操作同一个变量。
volatile 的原理
在 JVM 底层中,volatile采用内存屏障来实现的。内存屏障会提供3个功能:
- 确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面。
- 强制将对缓存的修改操作立即写入主内存;
- 如果是写操作,它会导致其他CPU中对应的缓存行无效。
锁框架
Lock接口提供了与synchronized关键字类似的同步功能,但需要在使用时手动获取锁和释放锁。
Lock 和 Condition 接口
以下是 Lock 接口的定义:
1 | public interface Lock { |
我们使用上述 lock() 和 unlock() 来演试一下:
1 | public static void main(String[] args) { |
和传统的synchronized相比,Lock 更像是锁,操作前加锁 lock(),操作后解锁 unlock(),结果和 synchronized 相同。
接下来,我们使用 Condition 来调用传统的 wait() 和 notify():
1 | public interface Condition { |
同样,我们也对 await() 和 signal() 进行测试:
1 | public static void main(String[] args) throws InterruptedException { |
可重入锁
可重入锁代表同一个线程能够进行多次加锁。
1 | public static void main(String[] args) { |
在线程持有锁的情况下,还可以继续加锁。通过 getHoldCount() 方法可以查看当前线程持有锁的数量。线程加了几次锁,那么对应的就要解几次锁,可以用 isLocked() 方法查看当前线程是否被锁定。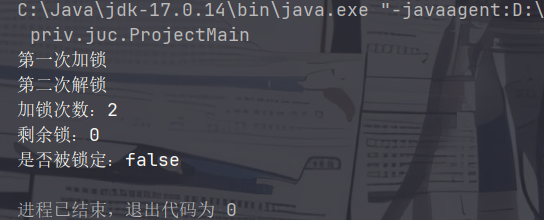
当一个线程持有当前的锁时,其他线程如果获取该锁,会进入等待队列,直到持有该锁的线程释放锁。
1 | public static void main(String[] args) throws InterruptedException { |
我们可以通过 getQueueLength() 方法查看等待队列的长度,并通过 hasQueuedThread() 方法判断某个线程是否在等待队列。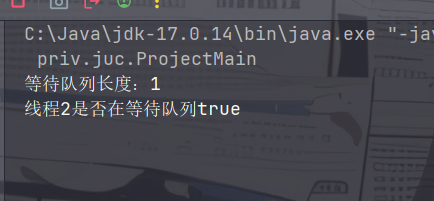
在 Condition 中,可以使用 getWaitQueueLength() 查看当前 Condition 有多少线程处于等待状态。
公平锁与非公平锁
公平锁指多个线程按照申请锁的顺序去获得锁,按进入等待队列的顺序得到锁。非公平锁是指多个线程在获取锁的时候,会尝试直接获取到锁,获取失败则会进入等待队列。ReentrantLock的构造方法提供了相关的实现:
1 | public ReentrantLock(boolean fair) { |
我们写一个测试案例:
1 | public static void main(String[] args) { |
对于公平锁,加锁和解锁的顺序是一致的。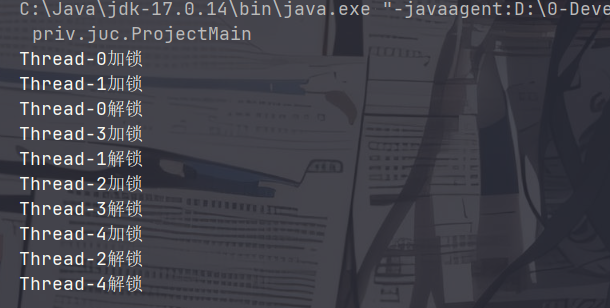
而对于非公平锁,加锁和解锁的顺序并不一致。(将构造方法的参数改为 false)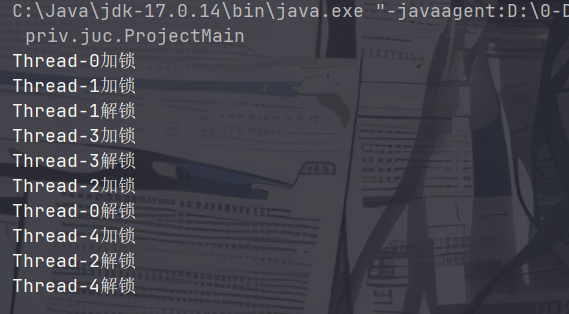
读写锁
读写锁维护了两个不同的锁:
- 读锁:在没有任何线程占用写锁的情况下,同一时间可以有多个线程加读锁。(共享锁S)
- 写锁:在没有任何线程占用读锁的情况下,同一时间只能有一个线程加写锁。(排他锁X)
读写锁提供了一个专门的接口:1
2
3
4public interface ReadWriteLock {
Lock readLock();
Lock writeLock();
}ReentrantReadWriteLock实现了这个接口,我们在操作读写锁时,需要先获取读锁或者写锁,然后才能进写 lock 操作。有线程有读锁的情况下,其他线程无法加写锁,反之,有写锁的情况下也无法加读锁:1
2
3
4
5public static void main(String[] args) {
ReadWriteLock lock = new ReentrantReadWriteLock();
lock.readLock().lock();
new Thread(() -> lock.readLock().lock()).start();
}如果出现了上述情况,或者有多个线程加写锁,都会导致程序不会终止,需要手动停止程序。1
2
3
4
5
6
7public static void main(String[] args) {
ReadWriteLock lock = new ReentrantReadWriteLock();
lock.readLock().lock();
new Thread(() -> {
lock.writeLock().lock();
}).start();
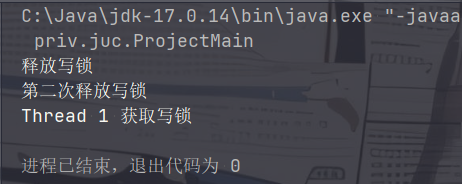
}ReentrantReadWriteLock还具有可重入锁的功能。例如:可以重复获取写锁,但必须全部解锁才能释放锁:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public static void main(String[] args) throws InterruptedException {
ReadWriteLock lock = new ReentrantReadWriteLock();
lock.writeLock().lock();
lock.writeLock().lock();
new Thread(()->{
lock.writeLock().lock();
System.out.println("Thread 1 获取写锁");
lock.writeLock().unlock();
}).start();
System.out.println("第一次释放写锁");
lock.writeLock().unlock();
Thread.sleep(10);
System.out.println("第二次释放写锁");
lock.writeLock().unlock();
}
同样的,读写锁也具有公平和非公平锁。
锁的升级和降级
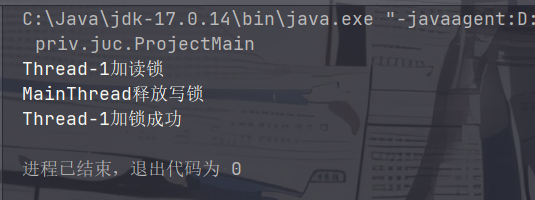
锁升级是指线程在持有读锁的情况下去获取写锁。而ReentrantReadWriteLock在读锁状态下无法加写锁,因此ReentrantReadWriteLock并不支持锁升级。
锁降级是指线程在持有写锁的情况下去获取读锁。虽然ReentrantReadWriteLock在其他线程具有写锁的情况下无法加读锁,但是在同一个线程中,是可以自己加读锁的。
1 | public static void main(String[] args) { |
再次强调,锁降级是指线程在持有写锁的情况下去获取读锁,而不是先释放写锁再获取读锁。
1 | public static void main(String[] args) throws InterruptedException { |
AQS 队列同步器
Lock 的底层实现来自 Sync 类,公平锁 FairSync 和非公平锁 NonFairSync 都继承自 Sync,而 Sync 类则继承自AbstractQueueSynchronizer,也就是队列同步器(AQS)。
底层实现
AQS 是实现锁机制的基础,内部已经封装好了例如加锁、解锁、等待队列等功能。等待队列是由双向链表实现的,每个等待状态线程都可以被封装进节点并放入双向链表,而对于双向链表则是以队列的形式进行操作的。等待队列是 AQS 的核心内容。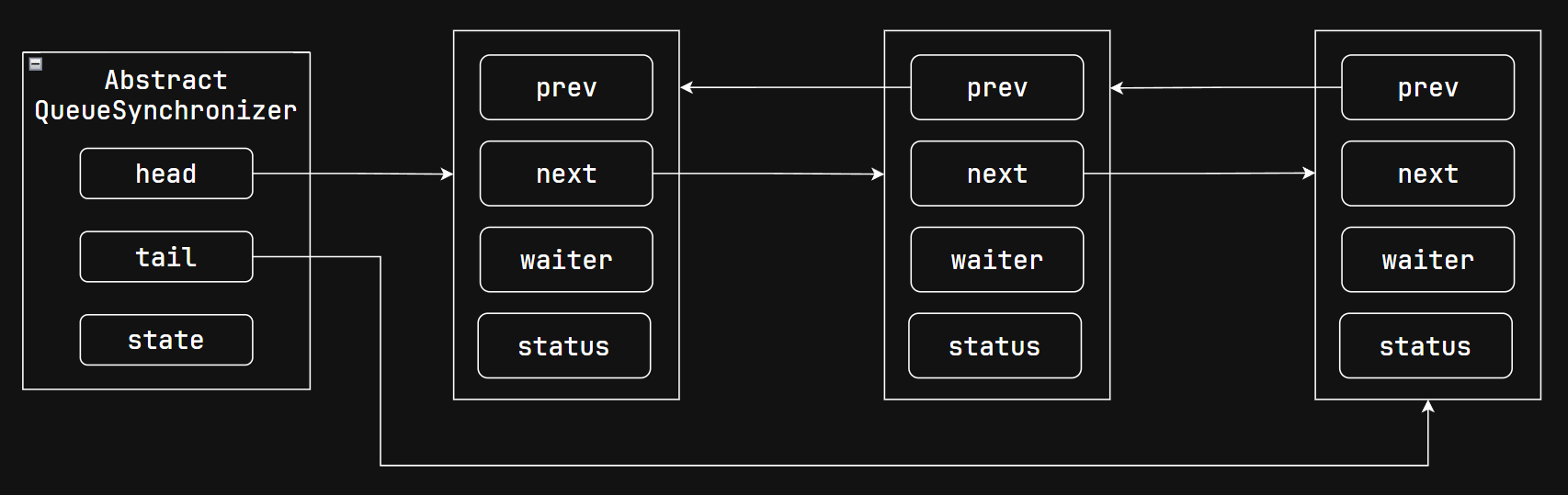
下面是AbstractQueueSynchronizer的部分源码:
1 | abstract static class Node { |
线程池
和数据库连接池相同,我们可以创建很多个线程组成线程池,反复地利用这些线程而不销毁它们。
由于线程池可以反复利用已有线程执行多线程操作,所以线程池一般是有容量限制的,当所有的线程都处于工作状态时,新的多线程请求会被阻塞,直到有一个线程空闲出来为止。
下面是线程池的某一个构造方法(参数最多的那个):
1 | public ThreadPoolExecutor(int corePoolSize, |
参数说明如下:
corePoolSize:核心线程池大小。向线程池提交一个多线程任务时,会创建一个新的核心线程,直到达到corePoolSize为止。然后会尝试反复利用这些线程。也可以在一开始就将核心线程全部初始化,使用prestartAllCoreThreads()即可。maximumPoolSize:最大线程池大小。当线程池中的所有线程都处于运行状态且等待队列已满,那么会创建非核心线程运行,直到达到maximumPoolSize为止。keepAliveTime:非核心线程最大空闲时间。当非核心线程超过一定时间未使用时将会被销毁。unit:keepAliveTime的时间单位。workQueue:等待队列。当线程池中核心线程已满时,会将任务存入等待队列,直到出现可用线程为止。(注意是核心线程不是最大线程,先进入等待队列,再创建非核心线程)threadFactory:线程创建工厂。用于自定义线程池中的线程创建过程。handler:拒绝策略。当线程池和等待队列都用完时,会采用拒绝策略,拒绝接下来的新任务。
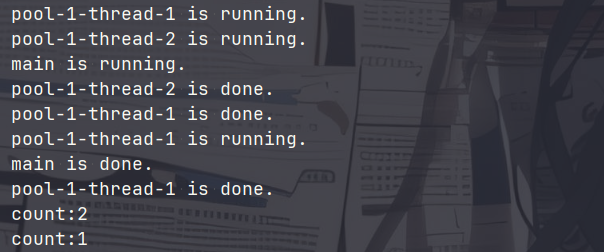
我们创建一个线程池模拟一下:我们创建了一个2核心、3最大线程数和2容量等待队列的线程池。执行任务时,核心线程先被占用,其余任务进入等待队列。但是等待队列容量只有2,此时还剩一个任务。由于线程数量不大于最大线程数,线程池会尝试创建非核心线程且成功创建,剩余的任务进入非核心线程。当出现空闲线程时,等待队列中的任务会进入空闲线程。直到所有线程都完成后,查询得到的线程池大小是核心线程与非核心线程数量的总和。等待3秒后,非核心线程被销毁,此时只剩下核心线程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public static void main(String[] args) throws InterruptedException {
// 2核心线程,3最大线程,3000ms空闲线程存活时间,等待队列容量为2
ThreadPoolExecutor pool = new ThreadPoolExecutor(1, 3, 3000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(2));
for (int i = 0; i < 5; i++) {
int count = i + 1;
pool.execute(() -> {
try {
System.out.println(count + " is running.");
TimeUnit.MILLISECONDS.sleep(100);
System.out.println(count + " is done.");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
}
TimeUnit.MILLISECONDS.sleep(600);
// 查看线程池中的线程数量
System.out.println("count:" + pool.getPoolSize());
// 超过空闲时间后的线程数量
TimeUnit.SECONDS.sleep(3);
System.out.println("count:" + pool.getPoolSize());
pool.shutdown();
}

除了自己创建线程池,Java 还提供了一些线程池定义,我们可以直接使用Executors工具类或者实现ExecutorService来使用这些线程池。
1 | ExecutorService single = Executors.newSingleThreadExecutor(); |
SingleThreadExecutor:只有1个核心线程的线程池,且最大容量也为1。FixedThreadPool:固定容量的线程池,核心线程数 = 最大容量 =nThreads。CachedThreadPool:缓存线程池。最大容量为Integer.MAX_VALUE,无核心线程,非核心线程最大空闲时间为60 seconds。ScheduledThreadPool:任务线程池。核心线程数为corePoolSize,最大容量和缓存线程池相同,非核心线程最大空闲时间为10 milliseconds。
线程池策略
当线程池没有容量时,会触发拒绝策略,默认会抛出RejectedExecutionException异常。线程池的拒绝策略默认有4种:
AbortPolicy:抛出异常。CallerRunsPolicy:让提交任务的线程执行该任务,而不是线程池。DiscardOldestPolicy:丢弃等待队列中最近的一个任务,替换为当前任务。DiscardPolicy:不做处理。
我们模拟一下啊CallerRunPolicy:不难发现,核心线程和等待队列是放不下4个任务,因此剩下的1个任务会让提交任务的线程执行,此处是主线程 main。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public static void main(String[] args) throws InterruptedException {
// 2核心线程,3最大线程,3000ms空闲线程存活时间,等待队列容量为2
ThreadPoolExecutor pool = new ThreadPoolExecutor(1, 2, 3000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(1), new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 4; i++) {
pool.execute(() -> {
try {
System.out.println(Thread.currentThread().getName() + " is running.");
TimeUnit.MILLISECONDS.sleep(100);
System.out.println(Thread.currentThread().getName() + " is done.");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
}
pool.shutdown();
}
我们将策略修改为DiscardOldestPolicy,会发现输出结果只有3个线程。因为受到该策略影响,等待队列里最近的一个任务被抛弃了,所以只会出现3个线程。(自行验证,不截图了)
线程创建工厂
我们可以实现ThreadFactory接口来自定义线程创建工厂,只需要实现 newThread 方法。
1 | ThreadFactory threadFactory = new ThreadFactory() { |
线程创建工厂就是线程池创建线程的方式。而如何创建这个对象,以及它的一些属性,都可以由我们自定义,最后返回一个 Thread 对象即可。
异常处理
如果我们提交的任务中出现了异常,那么执行这个任务的线程会被销毁,任务将由另一个线程执行。
有返回值的任务
我们可以使用Future来获取任务的返回值以及任务是否完成。
1 | public static ExecutorService single = Executors.newSingleThreadExecutor(); |
还可以使用FutureTask提前定义好任务。
1 | public static Future<Integer> calculate(int a, int b) { |
这样就将原本通过 submit() 隐式创建 Future 的过程,改为手动创建 FutureTask,明确包装任务逻辑。
FutureTask 还有以下优势:
- 生命周期控制:可以通过 isDone() 等方法直接监控或终止任务;
- 复用性:同一个 FutureTask 实例可以被多次提交;
- 灵活性:可以手动执行 FutureTask 的 run() 方法实现同步调用,但需要自行管理线程。
薛定谔的 FutureTask
FutureTask 的源码中,有一个private变量outcome,用于存放返回值。当任务执行时,该变量可能有值,也可能没有值(取决于哪个线程跑得快)。由于该变量是私有的,当我们想要获取该变量时,只能通过 get() 方法,而 get() 方法是阻塞的,所以当任务完成时,才会返回真实的值。
薛定谔的猫:你不看我,你怎么知道我是不是活着的。你看我,你就知道了🐶
定时任务
提交定时任务可以使用ScheduledThreadPoolExecutor,它继承自ThreadPoolExecutor,且最大线程池容量为Integer.MAX_VALUE,使用DelayWorkQueue作为等待队列。
1 | public static ScheduledThreadPoolExecutor pool = new ScheduledThreadPoolExecutor(1); |
schedule() 仅仅是多了两个参数,我们仍然可以使用 Future 来获取返回值。
我们还可以设置循环任务,每隔一段时间自动执行:
1 | // 2秒延迟后开始,然后每隔1秒执行一次 |
Java 还提供了预置的 newScheduledThreadPool() 方法用于创建定时任务线程池,具体的调用方法和上述相同。
1 | ScheduledExecutorService pool = Executors.newScheduledThreadPool(1); |
并发工具类
计数器锁 CountDownLatch
CountDownLatch用于实现子任务同步。
1 | // 创建计数器 |
await()可以被多个线程执行,一起等待,直到计数器为0时每个线程才会进行下一步。需要注意的是,创建的CountDownLatch对象只能用一次,归零后只能重新创建,不能重置。
循环屏障 CyclicBarrier
CyclicBarrier用于阻塞线程,直到被阻塞的线程达到CyclicBarrier设置的数量才会放行。
1 | CyclicBarrier barrier = new CyclicBarrier(3, ()->{ |
这里设置阻塞线程数为3,await() 会阻塞线程,直到被阻塞的线程有3个时才会放行。放行后屏障将重新开始计数,直到再次达到3个阻塞线程,然后放行,如此循环下去。
除了自动重置,我们还可以使用 reset() 方法手动重置,将会重新开始计数。在调用 reset() 后,处于等待状态下的线程将全部被中断并抛出BrokenBarrierException,然后屏障计数重置。
信号量 Semaphore
通过使用信号量,我们可以决定某个资源同一时间能够被访问的最大线程数。我们可以一开始就设定 Semaphore 的许可证数量,当许可证不足以供其他线程获取时,其他线程将被阻塞。
1 | Semaphore semaphore = new Semaphore(3); |
数据交换 Exchanger
Exchanger 用于实现线程之间的数据交换。
1 | Exchanger<String> exchanger = new Exchanger<>(); |
在一个线程调用 exchange() 方法后,该线程会等待其他线程调用同一个 Exchanger 对象的 exchange() 方法。当另一个线程也调用之后,双方线程分别得到对方传入的参数。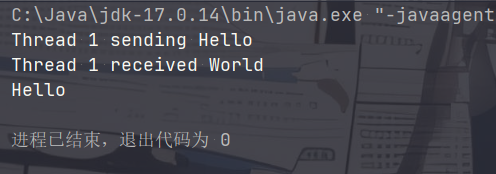
Fork/Join 框架
Fork/Join 目的是为了把大型任务拆分为多个小任务,最后汇总多个小任务的结果,得到整大任务的结果,并且这些小任务都是同时在进行,大大提高运算效率。Fork就是拆分,Join就是合并。
1 | public class JUC { |
上述任务成功的被分为了4个小任务执行,并且得到了正确的结果: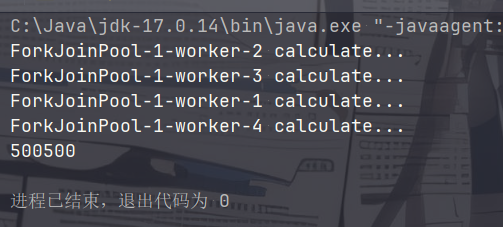
- 微信
- 支付宝

